Py
本文最后更新于 2025年11月7日 下午
Python学习笔记
学习笔记
正则常用匹配规则
| 模 式 | 描 述 | |
|---|---|---|
| \w | 匹配字母、数字及下划线 | |
| \W | 匹配不是字母、数字及下划线的字符 | |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f] | |
| \S | 匹配任意非空字符 | |
| \d | 匹配任意数字,等价于 [0-9] | |
| \D | 匹配任意非数字的字符 | |
| \A | 匹配字符串开头 | |
| \Z | 匹配字符串结尾,如果存在换行,只匹配到换行前的结束字符串 | |
| \z | 匹配字符串结尾,如果存在换行,同时还会匹配换行符 | |
| \G | 匹配最后匹配完成的位置 | |
| \n | 匹配一个换行符 | |
| \t | 匹配一个制表符 | |
| ^ | 匹配一行字符串的开头 | |
| $ | 匹配一行字符串的结尾 | |
| . | 匹配任意字符,除了换行符,当 re.DOTALL 标记被指定时,则可以匹配包括换行符的任意字符 | |
| […] | 用来表示一组字符,单独列出,比如 [amk] 匹配 a、m 或 k | |
| [^…] | 不在 [] 中的字符,比如 [^abc] 匹配除了 a、b、c 之外的字符 | |
| * | 匹配 0 个或多个表达式 | |
| + | 匹配 1 个或多个表达式 | |
| ? | 匹配 0 个或 1 个前面的正则表达式定义的片段,非贪婪方式 | |
| {n} | 精确匹配 n 个前面的表达式 | |
| {n, m} | 匹配 n 到 m 次由前面正则表达式定义的片段,贪婪方式 | |
| a | b | 匹配 a 或 b |
| ( ) | 匹配括号内的表达式,也表示一个组 |

- 修饰符

excel数据对象的方法
1 | |
to_list()
- 当你处理 pandas 的
Series(一维数据)或Index(索引)时,使用to_list()可以将其转换为普通的 Python 列表,方便进行一些原生列表支持的操作。
对 Series 使用 to_list ()
1
2
3
4
5
6
7
8
9
10import pandas as pd
# 创建一个 pandas Series
s = pd.Series([10, 20, 30, 40, 50])
print("原 Series 类型:", type(s)) # <class 'pandas.core.series.Series'>
# 转换为列表
lst = s.to_list()
print("转换后的类型:", type(lst)) # <class 'list'>
print("转换后的值:", lst) # [10, 20, 30, 40, 50]对 Index 使用 to_list ()
1
2
3
4
5
6
7
8
9
10import pandas as pd
# 创建一个 pandas Index
idx = pd.Index(['a', 'b', 'c', 'd'])
print("原 Index 类型:", type(idx)) # <class 'pandas.core.indexes.base.Index'>
# 转换为列表
lst = idx.to_list()
print("转换后的类型:", type(lst)) # <class 'list'>
print("转换后的值:", lst) # ['a', 'b', 'c', 'd']注意事项
to_list()是 pandas 特有的方法,普通的 Python 列表没有这个方法(会报错AttributeError)。- 转换后得到的是纯 Python 列表,不再具备 pandas 数据结构的特性(如索引、向量化操作等)。
- 在老版本 pandas 中,还有一个
tolist()方法(全小写),功能与to_list()完全相同,两者可以互换使用。
学习路线
1. GitHub 项目推荐:
这些项目都比较完整且适合用于学习高级技巧:
Scrapy
Scrapy 是 Python 中非常流行的爬虫框架,适合构建大规模、复杂的爬虫。Scrapy 提供了强大的功能,如异步下载、数据管道、内建的请求调度等,适合用来构建大规模的爬虫项目。pyspider
pyspider 是一个功能强大的爬虫框架,支持分布式爬虫、图形化界面、任务管理等。适合需要搭建爬虫平台的开发者。awesome-python-web scraping
这个项目是一个开源资源库,收集了 Python 爬虫相关的各种工具、框架和教程,非常适合你学习一些高级的技巧和工具。selenium
Selenium 是一个广泛用于 Web 自动化的工具。它也经常被用来做动态网页的爬取。对于一些 JavaScript 渲染的页面,Selenium 非常有用。Requests-HTML
一个简洁且强大的 HTML 解析库,支持现代网页中的 JavaScript 渲染。适合学习如何处理动态网页的抓取。
2. 书籍推荐:
这几本书会帮助你深入掌握 Python 爬虫的高级技巧:
《Python Web Scraping》 by Katharine Jarmul & Richard Lawson
这是一本系统性介绍 Web Scraping 的书,覆盖了使用 Requests、BeautifulSoup、Scrapy 和 Selenium 的技巧。对于中高级爬虫开发者来说,是一本非常实用的参考书。《Web Scraping with Python: Collecting Data from the Modern Web》 by Ryan Mitchell
这是一本非常经典的爬虫书籍,深入介绍了 HTML 解析、网页数据提取以及如何处理 JavaScript 渲染的页面(使用 Selenium)。它还讨论了爬虫的优化技术,比如异步爬取、缓存机制等,适合想深入学习爬虫的人。《Data Science for Web Scraping and Crawling》 by Jason Brownlee
本书侧重于如何在数据科学领域应用 Web Scraping 技术,特别是在处理大数据时的高效爬虫架构。《Scrapy for Beginners》 by Gabriel D. D.
这本书适合对 Scrapy 框架有一定了解的开发者。它不仅介绍了 Scrapy 的基本用法,还探讨了更高级的主题,比如 Scrapy 爬虫的分布式架构。
3. 在线教程和课程:
Scrapy 官方文档
Scrapy 的官方文档非常详细,适合初学者到高级开发者。通过文档,你可以深入了解 Scrapy 的各个组件,以及如何进行项目部署和优化。Real Python - Web Scraping Tutorials
Real Python 提供了很多关于 Web Scraping 的高级教程,内容涉及 Selenium、Scrapy、API 爬取等,讲解非常详细,并且有实际代码示例。Coursera - Python and Web Scraping
Coursera 提供了关于 Python 爬虫的多门课程,包括基础课程和进阶课程,适合需要系统学习的开发者。Udemy - Advanced Web Scraping with Python
这是一个付费课程,专注于爬虫的高级技巧,比如如何抓取动态内容,如何处理 AJAX 和 JavaScript 渲染的页面。
4. 学习路径:
基础阶段:
学习
requests和BeautifulSoup,理解 HTML 和 CSS,能够基本提取页面内容。学习如何使用正则表达式来抓取数据。
进阶阶段:
学习如何用
Scrapy框架构建爬虫,掌握其调度机制、管道机制以及分布式爬虫。深入了解如何绕过反爬虫机制,如 IP 代理池、验证码识别、动态渲染网页的抓取技巧(如使用 Selenium)。
学习如何优化爬虫,做到高效抓取(并发、异步处理、重试机制等)。
高级阶段:
掌握分布式爬虫的架构,如何进行分布式数据抓取和任务调度。
深入理解大规模数据的存储、处理与清洗,能够高效处理大量网页数据。
学习如何搭建爬虫平台,进行自动化和持续的抓取任务。
马斯克的学习方法
1. 自学是关键
主动学习:马斯克强调,自己大部分的知识都是通过阅读和自学获得的。他并没有在大学里专门学习物理、工程等领域的知识,而是通过大量阅读相关书籍、论文以及在线资源来获得这些知识。
书籍是最好的老师:马斯克是个狂热的书迷,很多他获得知识的渠道都是通过阅读专业书籍和技术论文。他提到自己从小就是通过阅读书籍来补充知识的,尤其是在技术和工程方面。
举例:
他曾说:“我并不是一开始就知道所有的东西,而是通过阅读积累知识。”
他提到过自己读过很多关于火箭、能源、汽车、人工智能等方面的书籍,甚至当他对某个领域感兴趣时,会集中精力大量阅读相关文献。
2. “第一性原理”思维
马斯克的一个标志性思维方式就是“第一性原理”思维(First Principles Thinking)。他认为,解决问题时要回到事物的最基础原理,从零开始重新思考,而不是依赖于已有的假设和常规做法。
第一性原理是从基础科学原理出发,分析一个问题的最基本构成要素,打破传统的框架和思维定势。这种方法促使他能够从根本上重新设计技术、产品和商业模式,突破已有行业的局限。
举例:
在SpaceX创建初期,马斯克认为火箭制造成本太高,他通过第一性原理的思维,分析了火箭的基本构成和材料,发现可以用更低的成本制造火箭。这直接促成了 SpaceX 的成功。
他还提到:“你需要把事情分解成最基本的原理,然后重新组合,得出一种更好的解决方案。”
3. 跨学科学习与应用
马斯克非常注重跨学科的学习,他的多个成功项目(如SpaceX、Tesla、Neuralink等)都显示了他将多个学科的知识进行结合的能力。
他通过从不同领域获取知识,能更好地解决问题,并能够发现并应用不同学科之间的联系和交集。
举例:
- 比如,他将物理学的原理应用到火箭设计中,并在Tesla的电动汽车设计中引入了很多工程学、能源学和计算机科学的概念,这些跨学科的知识使他能够打破传统设计局限,创造出创新的产品。
4. 批判性思维和怀疑一切
马斯克非常注重批判性思维,他认为任何既定的观点和假设都应该经受严苛的质疑。
他鼓励自己和团队成员要敢于质疑现状,不盲目接受传统做法,而是要提出新问题,寻找更高效、更创新的解决方案。
举例:
在创办 SpaceX 时,马斯克并没有接受航空航天行业的现状,而是反复质疑“为什么火箭这么贵”,“是否有更好的制造方式”。他不断质疑并用第一性原理重新思考,最终找到了更有效的制造火箭的途径。
他也曾提到:“我总是会问,‘这是为什么?’‘它是必须的么?’你要挑战那些看似理所当然的假设。”
5. 动手实践与快速原型
马斯克是典型的“做中学”型学习者。他认为,理论知识的掌握固然重要,但真正的理解来自于实践和动手做。
他鼓励团队进行快速原型制作和迭代,不断通过实际操作和实验来验证理论。
举例:
在 Tesla,他推动了“快速原型”开发的理念,团队会快速设计和测试新车型,并通过实际的试验来发现问题。
在SpaceX,他也同样采用了“快速原型”的方法,通过不断实验和迭代,减少了开发周期和成本。
6. 从失败中学习
马斯克对失败的看法非常独特,他认为失败是学习的一部分,而不是放弃的理由。他鼓励团队成员和自己从失败中吸取教训,并迅速调整策略。
他曾提到:“当你失败时,不要对自己太苛刻,最重要的是从失败中总结出教训,避免重复同样的错误。”
举例:
SpaceX 的火箭多次发射失败,马斯克并没有因此放弃,而是分析失败原因,改进设计,最终使 SpaceX 成为世界领先的私人航天公司。
在 Tesla 的初期,电动汽车面临巨大压力,许多投资者和评论家对其前景持悲观态度,但马斯克从失败中吸取了教训,不断迭代产品,最终使特斯拉成为全球最有价值的汽车公司之一。
7. 长期目标与持续学习
马斯克有非常明确的长期目标,并且他不断学习和调整自己的战略以实现这些目标。他并不是为了短期的成功而努力,而是为了更长远的理想(如人类在火星上定居、电动汽车普及等)而持续奋斗。
他认为,要达到这些长远目标,需要不断学习新的技能,吸收新的信息,扩展自己的视野。
举例:
- 马斯克的目标是将人类送上火星,他为了实现这个目标,不仅学习了航天工程学,还学习了很多其他与空间探索相关的知识,并将这些知识应用于 SpaceX 的开发中。
总结:马斯克的学习方法
自学为主:通过大量阅读书籍和在线资源不断获取新知识。
第一性原理:从最基础的原理出发,避免被传统思维束缚,创新解决方案。
跨学科学习:结合多个领域的知识,发现它们之间的联系,进行创新。
批判性思维:怀疑一切、挑战传统观念,寻找更好的方法。
动手实践:通过实际操作和快速原型开发来验证理论,并不断迭代。
从失败中学习:把失败视为学习的机会,从中吸取经验,不断改进。
长期目标与持续学习:不断学习新技能,为实现长期目标积累知识和经验。
书籍阅读推荐
🐍 Python方向书单
1️⃣ 基础 & 核心编程
🔑 目标:夯实 Python 基础,理解语法、面向对象、常用标准库
阶段 书名 适合人群 亮点 入门 《Python编程:从入门到实践(第2版)》 – Eric Matthes 0基础~初学 项目驱动+实用案例(数据可视化、Web应用) 入门 **《Python Crash Course》英文原版 英语+技术同步 示例代码简洁,练习丰富 进阶 《Fluent Python(流畅的Python)》 – Luciano Ramalho 已有基础 深入数据结构、迭代器、协程、元类,成为高级工程师必读 进阶 《Effective Python》 – Brett Slatkin 入门后半年~1年 90条最佳实践,代码风格提升
2️⃣ 数据分析(Numpy / Pandas / 数据可视化)
| 阶段 | 书名 | 亮点 |
|---|---|---|
| 入门 | 《利用Python进行数据分析(第2版)》 – Wes McKinney | Pandas作者亲自撰写,数据清洗/分析必读 |
| 进阶 | **《Python for Data Analysis》英文原版 | 与中文版对应 |
| 进阶 | 《Python Data Science Handbook》 – Jake VanderPlas | 包含NumPy、Pandas、Matplotlib、Scikit-Learn |
| 进阶 | 《Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow》 – Aurélien Géron | 从数据分析到AI的过渡 |
3️⃣ 制图 / 数据可视化
| 阶段 | 书名 | 亮点 |
|---|---|---|
| 入门 | 《Python数据可视化编程实战》 | Matplotlib、Seaborn、Plotly 案例 |
| 进阶 | 《Interactive Data Visualization for the Web》 | D3.js + Python后端 |
| 高阶 | 《Storytelling with Data》 | 数据可视化的设计与美学 |
4️⃣ 爬虫 / 网络数据获取
| 阶段 | 书名 | 亮点 |
|---|---|---|
| 入门 | 《Python3网络爬虫开发实战》 – 崔庆才 | 爬虫生态全景(requests、Scrapy、Selenium、Ajax) |
| 进阶 | 《Web Scraping with Python》 – Ryan Mitchell | 英文经典,结构化抓取 |
| 高阶 | 《黑客与画家》(补充) | 思维拓展,理解互联网数据逻辑 |
5️⃣ 自动化 & 工具开发
| 阶段 | 书名 | 亮点 |
|---|---|---|
| 入门 | 《Python自动化办公实战》 | Excel/PDF/邮件自动化 |
| 进阶 | 《Automate the Boring Stuff with Python》 – Al Sweigart | 文件、爬虫、脚本自动化 |
| 高阶 | 《Python Cookbook(第3版)》 | 配方式解决方案,开发效率倍增 |
🔑 成为高级工程师的路线
语言精通 → Fluent Python / Effective Python
数据处理能力 → Python for Data Analysis + Pandas/NumPy
项目经验 → 构建个人项目(爬虫+数据分析+可视化)
工程化 → 了解Git、Docker、CI/CD、云部署
软技能 → 英文阅读、代码规范、系统设计
Python库
1. 掌握常用的标准库
Python 本身就有很多非常有用的标准库,掌握它们可以帮助你高效地进行开发。以下是一些常用的标准库:
**
os和sys**:用于操作文件、目录,处理系统参数。**
datetime**:用于日期和时间的操作。math和 **cmath**:数学函数和复数运算。**
collections**:提供了如Counter、deque、OrderedDict等增强的数据结构。**
itertools**:用于高效地进行迭代操作,如生成组合、排列等。**
json**:用于处理 JSON 数据。**
csv**:处理 CSV 文件。**
sqlite3**:内置的 SQLite 数据库操作库。
学习方法:
Python 官方文档:https://docs.python.org/3/library/(这里有详细的库说明和示例代码)
《Python 标准库》(书籍)是学习这些库的好资源。
2. 数据分析相关库
如果你对数据分析、数据处理、可视化等感兴趣,可以学习以下库:
**
NumPy**:这是 Python 中用于数值计算的基础库,提供了多维数组和矩阵运算,支持大量的数学函数操作。**
Pandas**:用于数据处理和分析,特别适合处理表格数据,支持数据的清洗、聚合、过滤等。Matplotlib和 **Seaborn**:用于数据可视化,Matplotlib是基本的绘图库,Seaborn基于Matplotlib进行高级可视化。**
SciPy**:用于科学计算,提供了很多用于数学、科学和工程计算的功能。**
Scikit-learn**:用于机器学习,提供了许多常用的机器学习算法和工具。
学习方法:
NumPy 官方文档:https://numpy.org/doc/stable/
Pandas 官方文档:https://pandas.pydata.org/pandas-docs/stable/
Matplotlib 和 Seaborn 官方文档:https://matplotlib.org/stable/contents.html 和 https://seaborn.pydata.org/
书籍推荐:《Python 数据分析》(Wes McKinney)和《Python 机器学习》(Sebastian Raschka)
3. Web开发相关库
如果你对 Web 开发感兴趣,可以学习以下库:
**
Flask**:轻量级的 Web 框架,非常适合快速开发小型 Web 应用。**
Django**:功能强大的全栈 Web 框架,适合开发复杂的 Web 应用,提供了很多现成的功能。**
FastAPI**:新兴的 Web 框架,支持异步编程,性能极高,适合构建 API。**
Requests**:用于发送 HTTP 请求,处理 API 调用。**
SQLAlchemy**:ORM(对象关系映射)库,简化数据库操作。
学习方法:
官方文档:
Flaskhttps://flask.palletsprojects.com/、`Django` https://www.djangoproject.com/、FastAPIhttps://fastapi.tiangolo.com/书籍推荐:《Flask Web 开发》(Miguel Grinberg)、《Django 3 Web 开发实战》
4. 机器学习与深度学习相关库
如果你对机器学习、深度学习感兴趣,Python 提供了非常多的库来帮助你实现这些目标:
TensorFlow和 **PyTorch**:深度学习框架,用于构建神经网络和训练深度学习模型。**
Keras**:在 TensorFlow 上运行的高级深度学习库,简化了模型的构建和训练。**
scikit-learn**:机器学习库,提供了很多经典的机器学习算法和工具,适合用来构建各种模型。XGBoost和 **LightGBM**:高效的梯度提升算法库,特别适合处理大规模数据。**
OpenCV**:计算机视觉库,用于图像处理、对象识别等任务。
学习方法:
官方文档:TensorFlow、PyTorch、Keras、scikit-learn
书籍推荐:《Python 机器学习》(Sebastian Raschka)和《Deep Learning with Python》(Francois Chollet)
5. 自动化与脚本编写
如果你对自动化、爬虫或者脚本编写感兴趣,可以学习以下库:
**
Selenium**:自动化 Web 测试工具,也常用于 Web 数据抓取(爬虫)。**
BeautifulSoup**:一个简单易用的 HTML/XML 解析库,常用来处理 Web 数据抓取。**
Requests**:用于发送 HTTP 请求,结合爬虫库非常方便。**
Scrapy**:一个强大的 Web 爬虫框架,适合处理大规模的爬虫任务。
学习方法:
Selenium 官方文档:https://www.selenium.dev/documentation/en/
BeautifulSoup 官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
书籍推荐:《Python 网络数据采集》(Ryan Mitchell)
6. 如何学习这些库:
官方文档:大多数 Python 库都有非常详细的官方文档,学习它们的最佳方法之一就是阅读文档,官方文档通常包括了安装、使用示例以及一些常见问题的解决方案。
在线教程与课程:
Real Python:一个很棒的 Python 资源网站,提供了很多关于各个库和项目的教程。Real Python
Coursera、edX、Udemy 等平台也提供了大量与 Python 和相关库的在线课程。
GitHub 项目:很多开源项目都会在 GitHub 上提供代码示例,学习如何在实际项目中使用这些库是非常有效的方式。
做项目:最好的学习方法是通过实际做项目来巩固你学到的知识。选择一个感兴趣的领域(如数据分析、Web 开发、自动化等),然后动手编写代码,解决实际问题。
加入社区:Stack Overflow、Reddit、Python 官方论坛等社区也有很多开发者分享的经验和问题讨论,参与其中能快速提升自己的技能。
总结学习路线:
加强基础:继续练习 Python 基础知识,提升编程能力。
选择方向:
数据分析:学习 NumPy、Pandas、Matplotlib、Seaborn 等。
Web 开发:学习 Flask、Django、Requests 等。
机器学习/深度学习:学习 scikit-learn、TensorFlow、PyTorch 等。
自动化:学习 Selenium、BeautifulSoup、Scrapy 等。
动手实践:通过做项目来加深理解,并逐步提升技能。
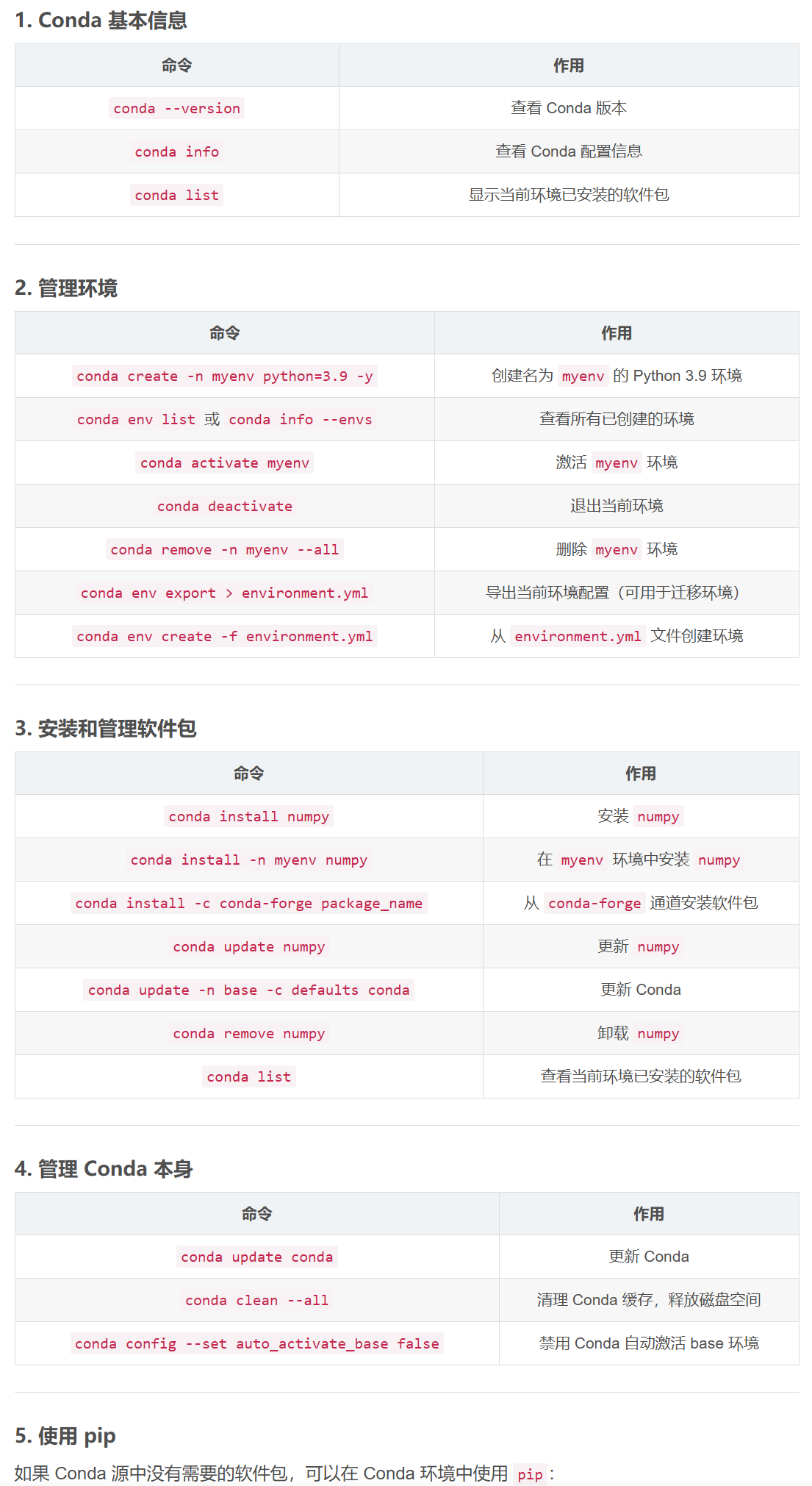
🐍 Conda 常用命令整理
1️⃣ 基本信息
| 命令 | 作用 | 示例 |
|---|---|---|
conda info | 查看 Conda 信息(版本、环境路径、渠道等) | conda info |
conda list | 查看当前环境已安装的软件包 | conda list |
conda list -n env_name | 查看指定环境的软件包 | conda list -n myenv |
conda config --show | 查看 Conda 配置 | conda config --show |
2️⃣ 环境管理
| 命令 | 作用 | 示例 |
|---|---|---|
conda create -n env_name python=3.11 | 创建新环境并指定 Python 版本 | conda create -n py311 python=3.11 |
conda activate env_name | 激活环境 | conda activate py311 |
conda deactivate | 退出当前环境 | conda deactivate |
conda remove -n env_name --all | 删除整个环境 | conda remove -n py311 --all |
conda env list | 列出所有环境 | conda env list |
conda env export > environment.yml | 导出环境(可备份或共享) | conda env export > env.yml |
conda env create -f environment.yml | 用 yml 文件创建环境 | conda env create -f env.yml |
3️⃣ 软件包管理
| 命令 | 作用 | 示例 |
|---|---|---|
conda install package_name | 安装包到当前环境 | conda install numpy |
conda install -n env_name package_name | 安装包到指定环境 | conda install -n py311 pandas |
conda update package_name | 更新包到最新版本 | conda update numpy |
conda update -n base conda | 更新 Conda 本身 | conda update -n base conda -y |
conda remove package_name | 卸载包 | conda remove numpy |
conda search package_name | 查找可用包及版本 | conda search numpy |
4️⃣ Conda 仓库管理(Channels)
| 命令 | 作用 | 示例 |
|---|---|---|
conda config --add channels channel_name | 添加渠道 | conda config --add channels conda-forge |
conda config --remove channels channel_name | 移除渠道 | conda config --remove channels conda-forge |
conda config --show channels | 查看当前渠道列表 | conda config --show channels |
conda tos accept --override-channels --channel <URL> | 接受服务条款 | conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/main |
5️⃣ 网络和缓存管理
| 命令 | 作用 | 示例 |
|---|---|---|
conda clean --all | 清理缓存和临时文件 | conda clean --all -y |
conda update -c defaults conda | 使用默认渠道更新 conda | conda update -n base -c defaults conda -y |
6️⃣ 高级操作
| 命令 | 作用 | 示例 |
|---|---|---|
conda list --explicit > spec-file.txt | 导出可精确重现环境的包列表 | conda list --explicit > spec.txt |
conda create --name new_env --clone old_env | 克隆已有环境 | conda create --name pyclone --clone py311 |
💡 小技巧
base 环境只管理 Conda 本身,不建议在 base 安装太多包
每个项目单独建环境 → 避免包冲突
尽量使用
conda-forge渠道 → 包更全、版本更新快遇到 Terms of Service 错误 → 用
conda tos accept接受条款
实战项目学习
🧭 一、入门友好:可直接上手的 Python 工具项目
这些项目适合你边学边做,能很快看到成果。
| 类型 | 项目名称 | 项目介绍 | 教程/源码 |
|---|---|---|---|
| 🧮 桌面计算器 | Simple Python Calculator | 用 tkinter 制作图形界面计算器 | GitHub 示例 |
| 📁 文件整理器 | File Organizer | 自动将文件分类到对应文件夹(比如按扩展名) | Real Python 教程 |
| 📸 图片批量重命名/压缩 | Image Tools | 用 Pillow 实现批量修改图片大小、格式 | Pillow 官方教程 |
| 📊 Excel 处理器 | Excel Cleaner | 用 pandas + openpyxl 清洗、合并、统计 Excel | GitHub: Excel Tool 示例 |
| ⏰ 倒计时/提醒小工具 | Countdown Timer | 制作一个命令行或 GUI 的倒计时器 | GeeksforGeeks 教程 |
| 🐍 贪吃蛇小游戏 | Snake Game | 用 pygame 实现经典贪吃蛇 | freeCodeCamp 教程 |
💡 二、练习思维:可以模仿和改进的 Python 实用工具项目
这些项目稍复杂一点,适合中级进阶,能让你理解 Python 的更多模块、库和架构。
| 项目类型 | 示例项目 | 功能简介 | 教程/源码 |
|---|---|---|---|
| 📬 邮件自动发送器 | AutoMailer | 自动向多个联系人发送邮件(支持附件) | GitHub: Auto Mailer |
| 🌦️ 天气查询工具 | Weather CLI | 命令行实时查询天气,使用 API 获取数据 | GitHub 示例 |
| 🔐 密码管理器 | Simple Password Manager | 用 cryptography 库实现本地密码加密存储 | RealPython 教程 |
| 🧾 PDF 处理工具 | PDF Merger | 批量合并/拆分 PDF 文件 | GitHub 示例 |
| 🧹 垃圾文件清理器 | Disk Cleaner | 扫描大文件、缓存文件并删除 | 可模仿 BleachBit 的结构 |
| 🤖 简易聊天机器人 | ChatBot | 用 nltk 或 transformers 制作一个简单对话机器人 | RealPython 教程 |
🧱 三、系统地发现项目和源码的网站推荐
这些网站持续更新 Python 项目、教程、源码,非常适合你“找灵感 + 看源码 + 跟着做”。
| 网站 | 特色 |
|---|---|
| 🐙 GitHub Topics: Python Projects | 官方分类页,汇总各类 Python 项目(有排序、标签) |
| 💡 Python Awesome | 专门收集优秀 Python 项目的网站(按主题分类) |
| 🧰 Real Python | 最好的 Python 教程网站之一,很多带源码的工具实战 |
| 🏗️ FreeCodeCamp Python Projects | 免费且详细的 Python 项目实战教程 |
| 🧑💻 Project-Based Learning | GitHub 上最全的项目实战合集(含 Python 专区) |
| 🎯 ThePythonCode.com | 实战性极强,比如爬虫、自动化、GUI 工具、网络安全脚本等 |
🧰 四、我的建议:学习路径
你可以这样安排学习:
1️⃣ 第1阶段(入门)
学习 tkinter、os、shutil、pandas 等库 → 做出文件整理器或计算器
2️⃣ 第2阶段(进阶)
学习 requests、BeautifulSoup、sqlite3、threading → 做出天气查询工具或爬虫
3️⃣ 第3阶段(应用)
尝试做带 GUI 的桌面应用,比如 Excel 统计器、下载器、小笔记软件等
命令
- pip freeze > requirements.txt 生成依赖的文件
Excel学习

Pandas
merge的用法
内连接:inner
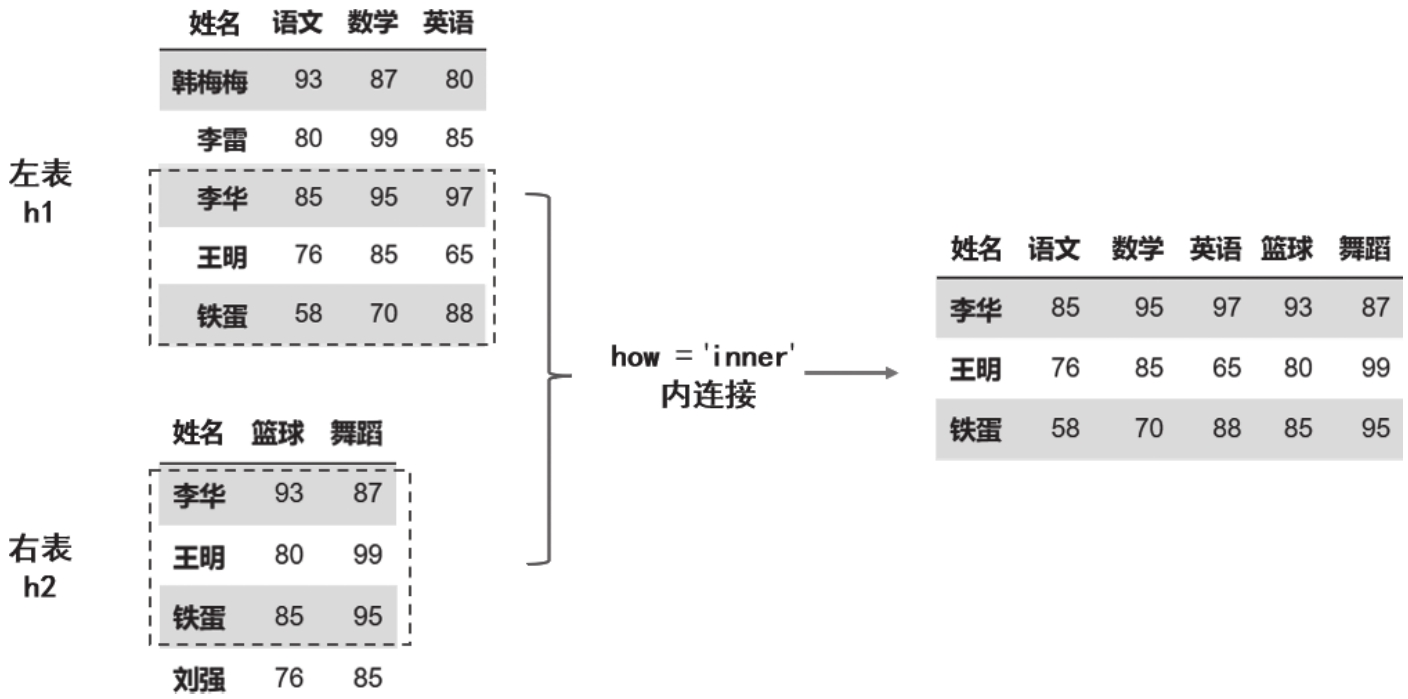
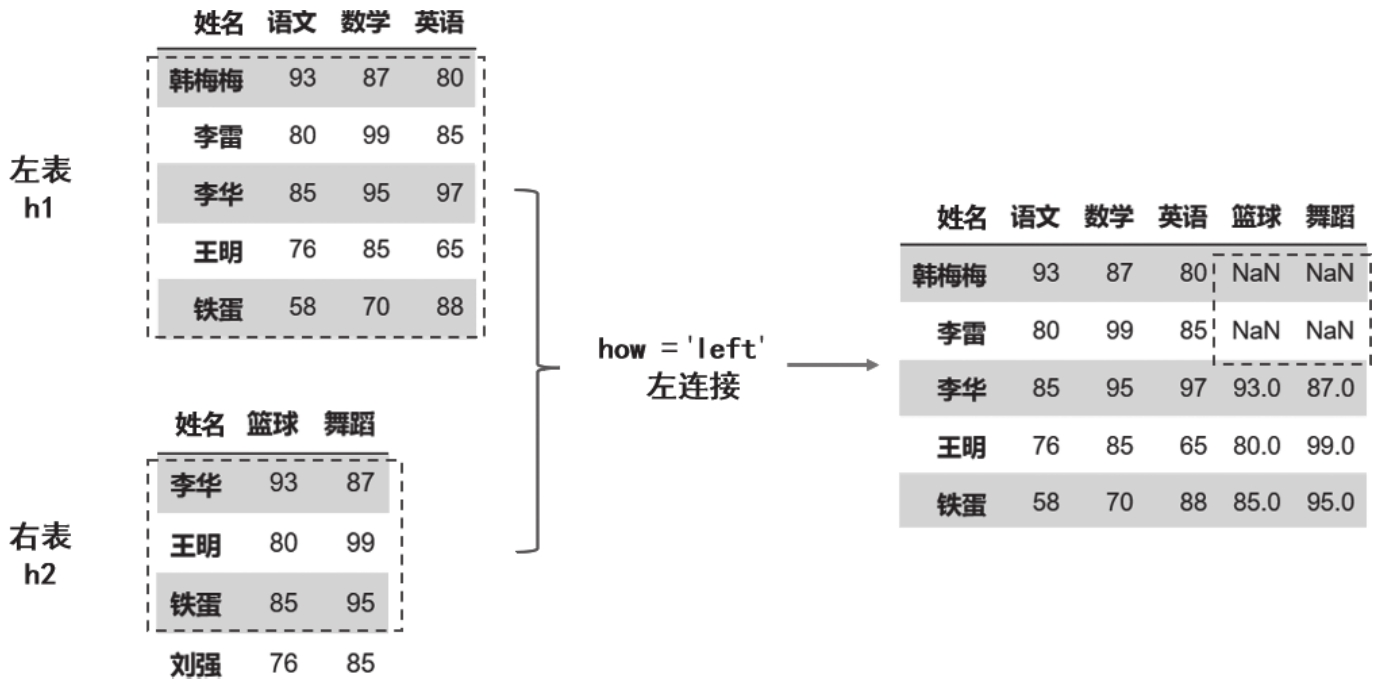
左连接:left
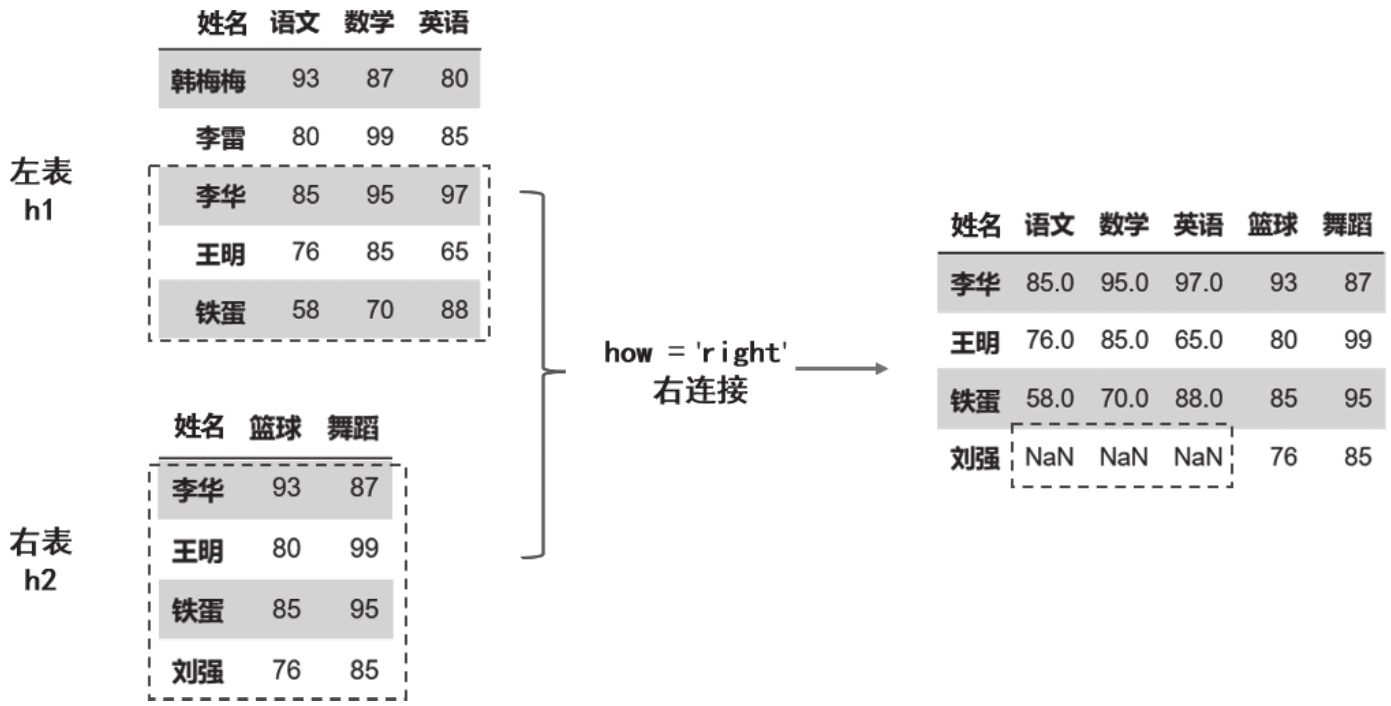
右连接:right
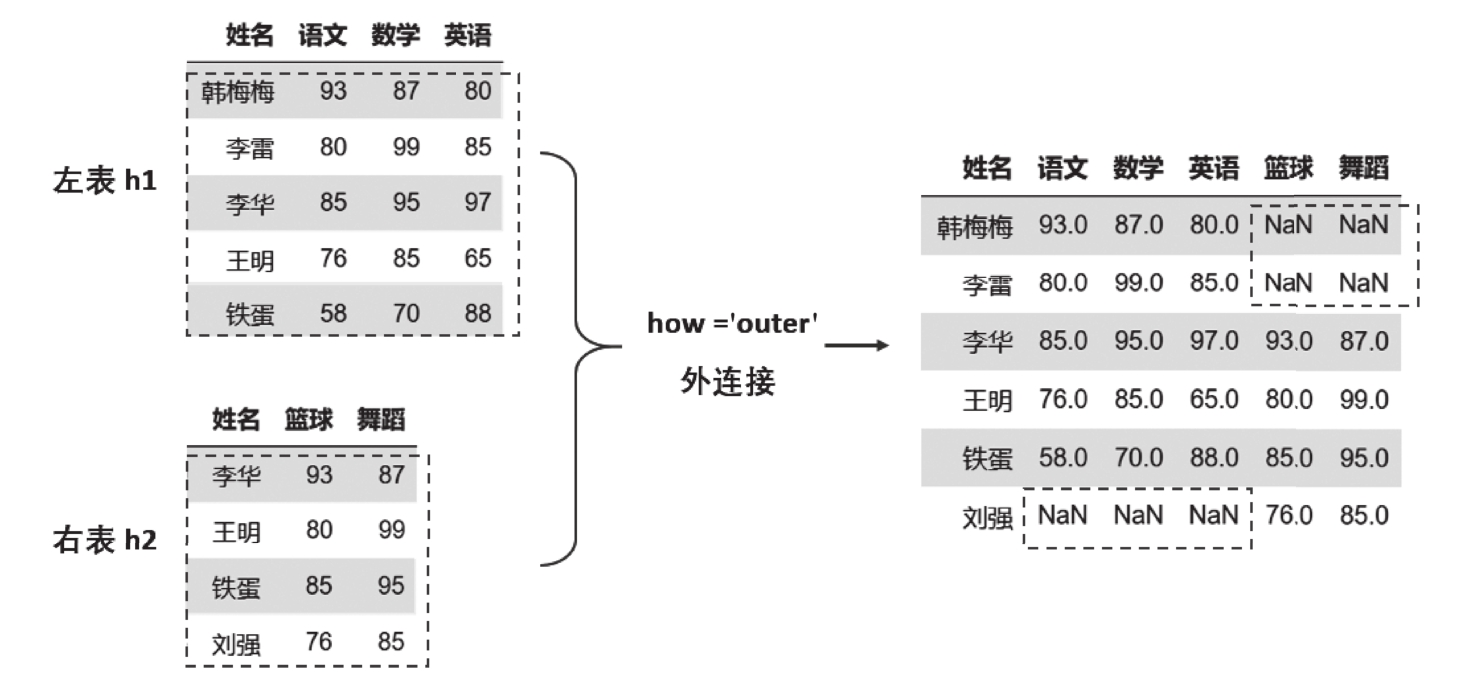
外连接:outer
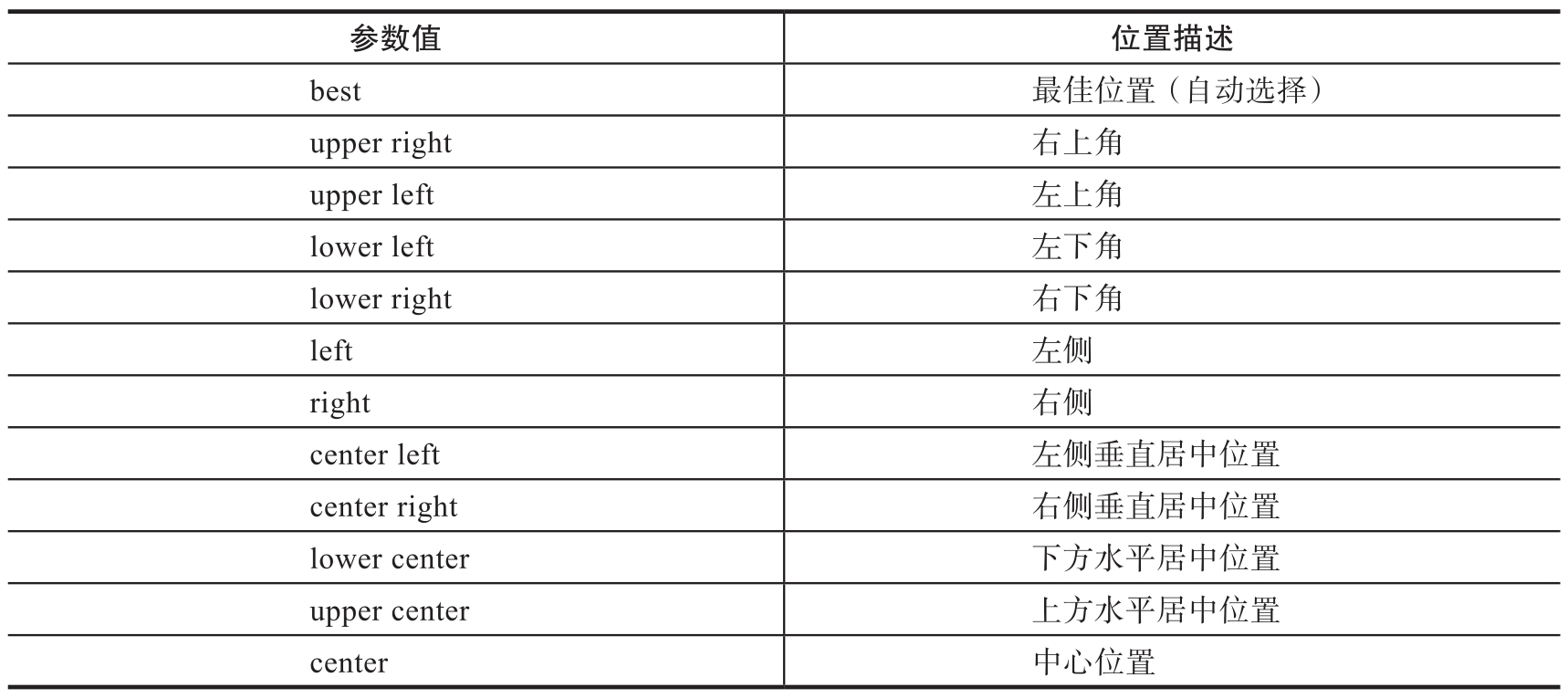
plt.legend(loc=?) 中loc参数的值以及描述
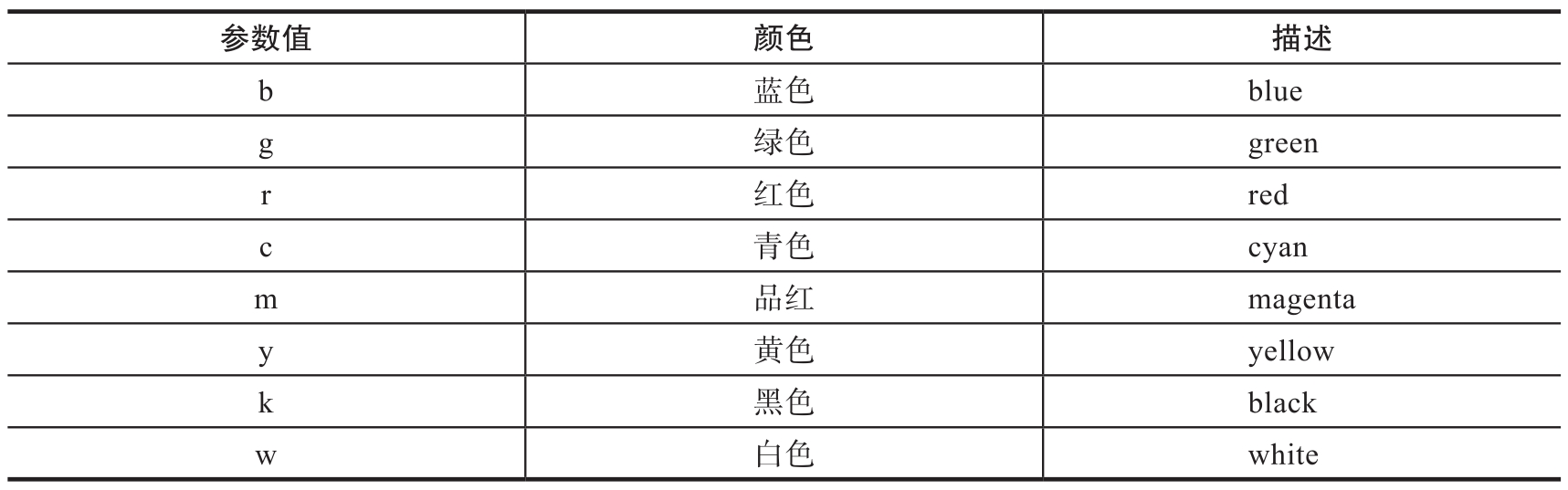
plt.plot()方法汇总

对应color参数
Jupyter
两种模式下的快捷键JupyterNotebook已经整理好
- 命令模式

- 编辑模式
